这几天,陆陆续续学完了“第7章 顶点着色器”和“第8章 片元着色器和表面外观”。基本上理解了什么是渲染管线,也明白了GPU编程与一般程序开发的差异。最让我高兴的是,终于明白了“平滑(Gouraud)着色”与“Phong着色”是什么意思,并且自己动手实现了一次ADS光照模型。
另外,为了弄清楚自己电脑支持的OpenGL和GLSL版本,找到了 Geeks3D 开发的 GPU Caps Viewer,挺好用的。
理解渲染管线
网上很多资料对渲染管线的介绍都很详细,因此我觉得自己没有必要再复述一遍。我想站在自己的角度,反思渲染管线出现的理由,以及发展的原因。
问题
假设没有GPU,没有着色器,如果我想开发一个3D图形程序,我需要做什么?哪怕就只是在屏幕上显示一个立方体,我该怎么做?
分析
程序是由数据结构和算法组成的。对于这样的一个3D图形程序来说,首先得有一种数据结构来存储这个立方体的信息,其次还得有一套算法将其绘制到平面上。
数据结构:点线面
我们可以把3D模型分解成点、线、面来存储。
存储“点”时,可以使用顶点在3D空间中的坐标来表示。要使用坐标,首先应该确立原点所在的坐标系统。没有参考坐标系,坐标是没有意义的。
public class Vector3f {
float x;
float y;
float z;
}
3D模型最基本的数据结构是顶点,每个模型都是有很多顶点组成的。对于一个立方体来说,至少得有8个顶点。
Vector3f[] vertexes = new Vector3f[8] {
new Vector3f(-1, -1, -1), // 0
new Vector3f(-1, -1, 1), // 1
new Vector3f(-1, 1, -1), // 2
new Vector3f(-1, 1, 1), // 3
new Vector3f(1, -1, -1), // 4
new Vector3f(1, -1, 1), // 5
new Vector3f(1, 1, -1), // 6
new Vector3f(1, 1, 1), // 7
};
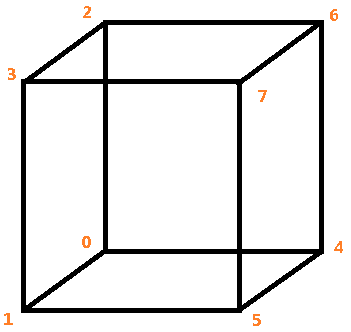
在已知顶点数组的前提下,“线”和“面”的存储就相对简单了。对于任意一个线段,只需要2个顶点的索引号就可以确定。
public class Line {
int vertexA;
int vertexB;
}
对于一个立方体来说,最少会有12个线条。可以用下面的方式来表达:
Line[] lines = new Line[12] {
new Line(0, 1), new Line(0, 2), new Line(2, 3), new Line(3, 1),
new Line(4, 5), new Line(4, 6), new Line(6, 7), new Line(7, 5),
new Line(0, 4), new Line(1, 5), new Line(2, 6), new Line(3, 7),
};
当然,其实这个Line结构完全没有必要存在,其实只需要一个整型数组就可以搞定了。
int[] lines = {
0,1, 0,2, 2,3, 3,1,
4,5, 4,6, 6,7, 7,5,
0,4, 1,5, 2,6, 3,7
};
那么“面”呢?
最简单的面是三角形(Triangle),只需要任意3个顶点的索引,就可以唯一确定一个三角形。
四边形(Quad)就不一定了。4个顶点不一定会共面,而且它们两两相连,会有不止一种连线方式。假如4个点不共面,甚至可能会形成一个四面体。

所以,在3D图形学中,三角形是最常用“面”。它的数据结构也很简单,只需要3个顶点索引号就可以表示一个三角形。
public class Triangle {
int vertexA;
int vertexB;
int vertexC;
}
那么多边形怎么表示呢?拆成多个三角形就好啦。比如立方体的每个面,都可以拆解成2个三角形。一个立方体有6个面,最少就需要12个三角形。
实际上,我们也没有必要定义Triangle类,只要用整形数组来存储这些索引号就行了。
int[] triangles = {
0,1,3, 0,3,2, // left
4,6,7, 4,7,5, // right
7,6,2, 7,2,3, // top
0,5,1, 0,4,5, // bottom
5,3,1, 5,7,3, // front
0,6,4, 0,2,6, // back
};
然后,为了区别线框模式和三角形格式,我们还可以定义一个变量,用来表示3D模型的顶点索引是如何组织的。
int mode = 3;// 3个索引为一组,表示三角形
上述的数据结构只是描述3D物体最基本的结构,但已经可以表达一些基本的思考方式了。
算法:空间变换
那么下面是绘制3D模型的算法问题。
首先要明确一个事实,3D模型位于3D空间中,而程序的画面是2D的。
这仿佛是一句废话,但却描述了3D图形算法的核心问题:投影。

我们需要计算3D模型的每个顶点在2D屏幕上的坐标,然后再根据这些坐标在屏幕上绘制线段、三角形和图像。为了让画面看起来更加真实,我们还必须模拟小孔成像的原理,使用“透视”方式来计算坐标,否则画面不会给人近大远小的感觉。
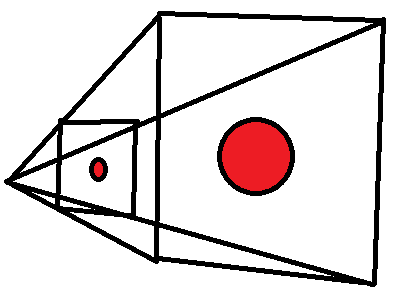
这个麻烦可就大了。3D坐标系统中的点,如何投影到一个2D坐标系统中?而且“透视”投影的过程居然还会导致物体变形(近大远小)!
我们需要一个投影函数,能够根据3D空间的坐标,计算出2D屏幕上的坐标。
// 计算模型到画面的投影坐标
Vector2f modelViewProjection(Vector3f vertex)
这个问题的本质是空间变形,三维空间的物体坍缩到二维空间。解决方法是矩阵,是线性代数。线性代数的研究对象是向量,向量空间(或称线性空间),线性变换和有限维的线性方程组。正好可以用来解决这个问题。
假设我们有这样一个矩阵,它代表按我们的意图把3D空间中的顶点投影到2D平面上,使用的感觉应该差不多是这个样子:
gl_Position = gl_ModelViewProjectionMatrix * gl_Vertex;
这里的 gl_Vertex 代表顶点的坐标,gl_ModelViewProjectionMatrix 代表模型投影矩阵, gl_Position 则代表计算的结果。
那么这矩阵是怎么来的?是根据摄像机的参数计算出来的,而且计算过程还涉及到四维空间。
现在,重点来了。
对于3D模型中的每一个顶点,我们都要使用这个投影矩阵来计算它的坐标。
这还不算完。为了让画面上的物体看起来更加真实,我们还需要根据光源信息计算每个顶点接受光照的强度,让物体表现出明暗的区别,否则人眼是看不出来3D效果的。

为此,我们还得计算每个顶点的法线,进而计算每个顶点的颜色。除此之外,还要对模型的顶点进行视锥裁剪,把不可能出现在画面上的顶点排除掉,避免没有意义的计算工作。还得区分模型的正面和背面,把背面剔除掉,免得画面上出现不该出现的内容。
这个过程说实话挺复杂的。假设3D模型由一万个顶点组成,那么就得把这个过程重复一万次。
算法:光栅化
通过一系列空间变换,我们得到了模型每个顶点在画面上的位置,接下来呢?
接下来该画线和面了。


上面两幅图是我们期待的画面,但这样的画面怎么才会出现呢?要知道,我们现在手上只有一堆顶点数据而已。
这时要用的方法,名为光栅化。对于已知两个点A(x1, y1)和B(x2, y2),要计算它们之间连线上所有像素的坐标和颜色。对于已知三角形A、B、C,要计算三角形内部每个像素的坐标和颜色。具体计算时,常常使用插值法。
随后,如果模型有对应的纹理贴图,还要插值计算每个像素的纹理坐标,然后从贴图中采集该像素点的颜色值。
这个计算量有多大呢?视画面的分辨率而定。因为此时的计算时以像素为单位的,画面的分辨率越大,像素越多,计算量就越大。
显卡与固定功能管线
根据前面的分析,我们至少了解了一个事实:3D图形程序需要大量的运算,大量的浮点运算、向量运算、矩阵运算。
这种计算工作对CPU来说是小菜一碟,但是架不住量太大。这就像逼着一个大学教授去做初中的数学题,问题不在于解一道题的速度快慢,在于题目数量的多少。
为了加速这个计算过程,GPU诞生了。显卡,或者说GPU,和CPU最大的区别在于,它阉割了很多CPU的控制功能和调度功能,转而强化了并行计算功能。假设每个CPU上只有1个计算单元,那么GPU上可能有100个。打个比方,1名教授做100道初中题所花的时间,不如让100个中学生每人做1题更快。
3D图形程序中很多运算都是相似的,只是参数有所不同。比如3D模型的每个顶点都要进行相似的投影运算,区别仅仅是顶点坐标不同;画面上的每个像素都要进行插值运算,区别仅仅是坐标不同。
为了加速图形程序的计算速度,早期的显卡干脆把一些常用的功能做到硬件上,形成了固定管线。如果想要使用硬件加速,就在程序中去调用这些功能,实现不同效果就好像在电路中打开不同的开关。
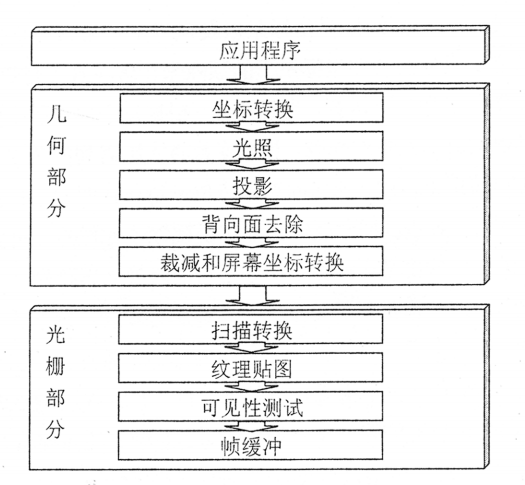
扩展阅读:
着色器的工作方式
注意,重点来了!!
不管是过去的“固定功能管线”还是现在的“可编程渲染管线”,GPU的核心能力始终都是并行计算!!
因此,GPU中基本上不存在for循环、while循环之类的功能,因为它不需要!这于我们平时写代码的习惯迥然相异。如果在CPU中我们需要计算100个顶点,代码一般是这样写的:
for(int i=0; i<100; i++) {
Vertex v = ary[i];
// 计算..
}
GPU里面不是这样的。GPU希望你把这100个顶点数据全部提交给他,然后并行调度。它可能会为这个计算任务分配十几个计算单元,每个计算单元分别取一个顶点的值进行计算。等100个顶点都计算完了,GPU再把结果返回给你。
我们所编写的顶点着色器(Vertex Shader)或片源着色器(Fragment Shader),在工作的时候,接受的数据永远都是单个顶点或单个像素。
可以把整个Vertex Shader理解成一个函数:一个顶点输入进来,经过一定的计算,再输出变换后的结果。这个函数将会在GPU的每个计算单元中并行执行,因此执行速度比CPU快得多。
同理,Fragment Shader也可以理解成一个函数,它的输入是每个像素点的参数,输出的结果是计算后的颜色和深度值。当渲染管线执行完光栅化操作后,就会开始并行调用大量计算单元来执行这个函数,用来计算画面上每个点的颜色。
不过着色器也不是万能的,比如背面剔除、Alpha混色、深度测试、模板测试、光栅化这些功能,都是GPU内置的,无法通过编程来控制。在使用这些功能时,有时依然像在电路中打开不同的开关一样。
举个例子,jME3的 Material 对象提供了一个getAdditionalRenderState() 方法,可以让我们设置一些额外的渲染状态(RenderState)。这所谓的 RenderState,其实就是 GPU 中的那些固定功能。
光照模型
在理解了着色器的工作方式后,我又进一步学习了光照模型。
固定着色
这倒没有什么特别好说的。在固定功能管线时代,显卡会把光照计算做成固定功能,称为固定着色。
平滑(Gouraud)着色
平滑着色是由Gouraud提出的一种算法,核心是 ADS 光照模型。它工作在顶点着色器中,先根据ADS模型计算出每个顶点的光照颜色,再经过GPU插值计算出每个像素的颜色,表现为平滑着色的效果。
Phong着色
Phong也是一个人的名字。这种着色的核心同样是 ADS 光照模型,但是它工作在片元着色器中,计算量比Gouraud着色大4~5倍。它不依赖插值计算像素颜色,而是直接根据每个像素的光照、法线来计算光照颜色。
着色器代码
下面是我根据教材上介绍的算法实现的Phong着色器程序。根据书上的要求,我做了一点改动,主要是把光源位置、ADS的3种光照、3种材质颜色都做成了uniform变量,允许用户实时调整参数。
Phong.glib
#使用透视相机,夹角90°
Perspective 90
#从(0, 0, 3)处看向(0, 0, 0)处,(0, 1, 0)为UP方向。
LookAt 0 0 3 0 0 0 0 1 0
Vertex Phong.vert
Fragment Phong.frag
Program Phong \
uLightPosition {10, 20, 30, 1} \
uAmbientLight {0.2, 0.2, 0.2} \
uDiffuseLight {1.0, 1.0, 1.0} \
uSpecularLight {1.0, 1.0, 1.0} \
uAmbientColor {1.0, 0.8, 0.0} \
uDiffuseColor {1.0, 0.8, 0.0} \
uSpecularColor {1.0, 1.0, 1.0} \
uShininess <1.0, 16.0, 128.0>
Teapot
Phong.vert
#version 140 compatibility
//uniform mat4 uModelViewProjectionMatrix;
//uniform mat4 uModelViewMatrix;
//uniform mat3 uNormalMatrix;
uniform vec4 uLightPosition;
varying vec3 vPosition;
varying vec4 vColor;
varying vec3 vNormal;
varying vec2 vTexCoord;
void main() {
vNormal = normalize( gl_NormalMatrix * gl_Normal );
vPosition = vec3(gl_ModelViewMatrix * gl_Vertex);
vTexCoord = vec2(gl_MultiTexCoord0);
vColor = gl_Color;
gl_Position = gl_ModelViewProjectionMatrix * gl_Vertex;
}
Phong.frag
#version 140 compatibility
uniform vec4 uLightPosition;
// Light Colors
uniform vec4 uAmbientLight;
uniform vec4 uDiffuseLight;
uniform vec4 uSpecularLight;
// Material Colors
uniform vec4 uAmbientColor;
uniform vec4 uDiffuseColor;
uniform vec4 uSpecularColor;
uniform float uShininess;
varying vec3 vPosition;
varying vec3 vNormal;
varying vec4 vColor;
varying vec2 vTexCoord;
// ADS光照模型
vec3 ADSLightModel(in vec3 myNormal, in vec3 myPosition) {
// 顶点法线
vec3 normal = normalize(myNormal);
// 顶点到光源方向向量
vec3 lightVector = normalize( uLightPosition.xyz - myPosition );
// 顶点到眼睛方向向量
vec3 eyeVector = normalize( vec3(0.) - myPosition );
////// ambient 环境光 //////
vec3 ambient = (uAmbientColor * uAmbientLight).rgb * uAmbientLight.a;
////// difffuse 漫反射光 //////
// 根据余弦值,计算漫反射光强度
float diffuseInsentity = dot(lightVector, normal);
vec3 diffuse = (uDiffuseColor * uDiffuseLight * diffuseInsentity).rgb * uDiffuseLight.a;
////// specular 高光 //////
vec3 specular = vec3(0.);
if (dot(lightVector, eyeVector) > 0.) {// 光线与视线夹角 < 90°
// 根据光线方向和法线方向,计算反射方向
vec3 refl = reflect( vec3(0.) - lightVector, normal );
// 计算反射光与视线夹角的余弦值
float cosin = dot(refl, eyeVector);
if (cosin > 0.) {// 夹角 < 90°
// 计算高光强度
float specularInsentity = pow(cosin, uShininess);
specular = (uSpecularColor * uSpecularLight * specularInsentity).rgb * uSpecularLight.a;
}
}
return clamp(ambient + diffuse + specular, 0., 1.);
}
void main() {
vec3 color = ADSLightModel(vNormal, vPosition);
gl_FragColor = vec4(color, 1.);
}