第十四章:Java I/O流
有一个笑话是这样的:
问:要把大象装冰箱,一共分几步?
答:分三步,一把冰箱门打开,二把大象放进去,三把冰箱门关上。
这个笑话的无厘头之处在于,正常人都明白把大象放进冰箱是最难的,而打开、关上冰箱门根本不算事。回答的人却一本正经地把它们放在一起说,仿佛把大象放进冰箱是像打开冰箱门一样简单的问题。
Java 的 I/O 流也分三步,一打开I/O流,二读/写数据,三关闭I/O流。与开头的笑话恰恰相反,I/O操作最复杂的是第一步。相比之下,读写数据几乎不算事。
复杂的主要原因,是Java在设计时对文件读写进行了高层抽象,统一为InputStream 和 OutputStream。这个设计的初衷是想统一文件、网络、设备、内存等不同来源的I/O操作,但是却忽略了实际每一种I/O操作都有特殊的需求,导致I/O包下的继承层次尤其复杂。
jME3 的资产管理是建立在 Java 的 I/O 机制之上的。考虑不少学习使用jME3的用户都是刚学习Java不久的人,我认为有必要对 Java 的 I/O 流知识做一些介绍,避免一些读者在阅读后续章节时可能产生的不适感。
但我不准备把本文写成Java I/O教程,而是假设读者有Java I/O的概念,至少会用 FileInputStream 来读文件。在这个基础上,我会分析 InputStream 和 OutputStream 最核心的用法,再进一步阐释用 I/O 来读取游戏资产时可能需要用到的方法。
如果读者的Java I/O基础比较好,可以直接跳过本章去看后面的内容。如果读者觉得本章内容太长,也可以直接跳到后面的文章。
等读到自己不太理解的内容时再回过头来看这一章,也许才能有所体会。
输入流
示例代码
先贴一段简单的代码。
public static void main(String[] args) {
String result = null;
try {
// 打开输入流
InputStream in = new FileInputStream("index.html");
int len = in.available();
System.out.println("总字节数: " + len);
// 读取数据
byte[] data = new byte[len];
in.read(data, 0, len);
len = in.available();
System.out.println("剩余字节: " + len);
result = new String(data);
// 关闭输入流
in.close();
} catch (IOException e) {
e.printStackTrace();
}
// 打印结果
System.out.println(result);
}
这是一段常见的Java读文件代码。它从磁盘上读取了一个名为 index.html 文件,并把数据转成字符串输出到控制台。(该文件是从 https://github.com/jmecn/jmecn.github.io/blob/master/index.html 复制的。)
运行结果:
总字节数: 10958
剩余字节: 0
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="utf-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1">
...略
代码分析
这段代码可以分解成三个阶段:
1.打开文件
// 打开输入流
InputStream in = new FileInputStream("index.html");
2.读文件
int len = in.available();
System.out.println("总字节数: " + len);
// 读取数据
byte[] data = new byte[len];
in.read(data, 0, len);
len = in.available();
System.out.println("剩余字节: " + len);
3.关闭文件
// 关闭输入流
in.close();
打开文件和关闭文件分别只有一行代码,就不多解释了。分析一下读文件的代码,会发现其实只使用了 InputStream 的 in.available(); 和 in.read(data, 0, len); 这两个方法。
available() 方法的作用是告知我们输入流中还有多少数据可读。假设文件的长度是 10958 字节,调用 read(data, 0, 1024) 方法读取了 1024 字节后,就还剩 9934 = 10958 - 1024 个字节可读。
对于文件输入流(FileInputStream)来说,如果在调用 read() 方法前先调用 available() 方法,由于此时文件数据还没有被读取过,available() 返回的就是文件的总长度。
int len = in.available();
System.out.println("总字节数: " + len);
根据 len 的值,就知道需要分配多少内存来存储文件数据。
// 读取数据
byte[] data = new byte[len];
然后调用 read() 方法读取数据,保存到数组 data 中。
in.read(data, 0, len);
再次调用 available() 方法,可以获得文件中剩余的字节数。
len = in.available();
System.out.println("剩余字节: " + len);
拿到数据后,就可以转成字符串输出。
result = new String(data);
// 打印结果
System.out.println(result);
分段读取
上面的代码是不是很简单?**然而这个代码是有缺陷的,**最大的缺陷是忽略了文件的大小。
通常情况下,计算机的硬盘空间会比内存大很多。假如程序要读取的是一个3GB大小的文件,而Java虚拟机只有2GB内存,上面的代码运行时就会...Booooom...内存炸了。
更好的做法是把数据切成可控的“小块”来读取,一边读取一边使用。例如循环读取1KB数据,直到文件数据被全部读完为止。
改造例一中的读文件代码:
int len = in.available();
System.out.println("总字节数: " + len);
StringBuffer sb = new StringBuffer();
// 读取数据
len = 0;
byte[] data = new byte[1024];// 1KB
while( (len = in.read(data, 0, 1024)) != -1) {
sb.append(new String(data));
System.out.printf("读取: %d 剩余: %d\n", len, in.available());
}
result = sb.toString();
运行结果:
总字节数: 10958
读取: 1024 剩余: 9934
读取: 1024 剩余: 8910
读取: 1024 剩余: 7886
读取: 1024 剩余: 6862
读取: 1024 剩余: 5838
读取: 1024 剩余: 4814
读取: 1024 剩余: 3790
读取: 1024 剩余: 2766
读取: 1024 剩余: 1742
读取: 1024 剩余: 718
读取: 718 剩余: 0
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="utf-8">
...略
这段代码并没有解决我刚才说的“内存爆炸”问题,文件数据全部都被写到了 StringBuffer 中,该炸还是会炸。但这只是因为我懒得处理数据的取出,不是重点,重点是这一段代码。
// 读取数据
len = 0;
byte[] data = new byte[1024];// 1KB
while( (len = in.read(data, 0, 1024)) != -1) {
sb.append(new String(data));
System.out.printf("读取: %d 剩余: %d\n", len, in.available());
}
根据我多年的经验,这是Java学生在学I/O流时最头疼的一段代码。首先要搞明白这段代码做了什么,然后再来分析它是怎么做的。
这段代码的作用,就是我刚才说的:把数据切成可控的“小块”来读取,一边读取一边使用。
首先,分配了一个固定大小的字节数组,作为读数据的缓存。
byte[] data = new byte[1024];// 1KB
然后,在循环中读取数据,每次读1KB大小,直到读完为止。
while( (len = in.read(data, 0, 1024)) != -1) {
sb.append(new String(data, 0, len));
System.out.printf("读取: %d 剩余: %d\n", len, in.available());
}
要看懂这个代码,必须理解 read 方法具体是怎么工作的。
read(byte b[], int off, int len) 方法的作用是从输入流中读取 len 个字节,并把数据写入到字节数组b中,并返回实际读取了多少数据。如果没有读取到任何数据,意味着文件已经读取完毕,返回 -1。
如果 len 的值是 10958,而字节数组b的长度是 1024,显然不可能把全部数据都写入到 b 中,最多只能读取 1024 字节,此时 read() 方法的返回值是 1024。参数len的值为1024时,就是希望每次读取1024个字节。
这是控制台中的输出:
总字节数: 10958
读取: 1024 剩余: 9934
读取: 1024 剩余: 8910
读取: 1024 剩余: 7886
读取: 1024 剩余: 6862
...
当输入流中的可用数据不足 len 个字节时会怎么样呢?就像我买了一根11米长的绳子,打算剪成3米长的跳绳,总会有一段绳子不足3米长吧?
观察下面的输出。
读取: 1024 剩余: 1742
读取: 1024 剩余: 718
读取: 718 剩余: 0
当文件被多次读取后,最后还剩 718 字节,不足1KB。此时 data 中只读取了 718 个字节,read() 方法返回实际读取字节数。
在 while 循环中, len = in.read(data, 0, 1024) 语句的作用是尝试从输入流中读取1KB数据,保存到数组data中,len 记录了实际读取的字节数。如果可用数据不足1KB,就只读取可用的数据。
因为实际读取的字节数可能比数组data的长度小,所以不能直接把整个数据中的全部数据当做有效数据去使用。这时候 len 的作用就体现出来了,它约束了实际使用的字节数量。
sb.append(new String(data, 0, len));
(len = in.read(data, 0, 1024))是一个赋值表达式,返回的是len的值。
(len = in.read(data, 0, 1024)) != -1 是一个逻辑表达式,作用是判断 len 的值是否为 -1。根据前面的介绍,len 等于 -1 时,说明文件已经读完了,就应该终止循环。
所以这个while循环内干了好几件事:一、从输入流读取1KB数据;二、用len记录实际读取了多少字节;三、根据len 的值是否为-1来判断文件是否读完了。
while ((len = in.read(data, 0, 1024)) != -1) {
// ..
}
下标偏移
read(byte b[], int off, int len) 方法的第二个参数 off,是一个下标偏移量(offset)。有时候,可能数组b中已经存储了一部分数据,我们不希望把它给覆盖了。这时候就不能从数组下标0开始读取数据,需要一个下标偏移量。
这就像两个油漆工合作刷一面墙,双方约定好一个刷蓝色,另一个刷红色。在开工之前应该约定互相工作的范围。不能一个人先把墙刷蓝了,另一个人再把他刷过的地方涂成红色,那这面墙就脏了。
例如要分别读2个文件,写到同一个数组b中。文件1的长度是666,文件2的长度是233,数组b的总长度应该是899。
假如代码像下面这样写,就会出问题:
in1.read(b, 0, 666);
in2.read(b, 0, 233);
b 先从 in1 中读取了 666 个字节,然后又从 in2 中读取了 233 个字节。第二行代码执行时,先读取的 666 字节前面被覆盖了 233 个字节。
第二次读取数据时,应该从第一次读取后的位置继续读取,而不是从0处开始读取。
in1.read(b, 0, 666);
in2.read(b, 666, 233);
假设定义字节数组 byte[] data = new byte[1024],执行方法 len = in.read(data, 233, 1024);,len 的值是多少呢?
这个方法的含义,是尝试从输入流中读取1024字节数据,保存到数组data中,从数组下标233处开始保存。由于data的长度是1024,从下标233到下标1023处一共只剩下 801 = 1024-233 字节,因此最多只能读取801字节。如果输入流可用字节数少于801,最终能够读取到的数据会更少。
读取用户输入
我们都很熟悉 System.in,它是Java系统内置的输入流,功能是读取控制台输入。
public static void main(String[] args) {
try {
// 打开输入流
InputStream in = System.in;
// 打开输出流
OutputStream out = System.out;
// 读取数据
int len = 0;
byte[] data = new byte[1024];// 1KB
while( (len = in.read(data, 0, 1024)) != -1) {
// 写数据
out.write(data, 0, len);
System.out.printf("读取: %d 剩余: %d\n", len, in.available());
}
// 关闭输入流
// in.close();
} catch (IOException e) {
e.printStackTrace();
}
}
这段代码在运行时,会阻塞在 in.read(data, 0, 1024) 这一行,因为系统会等待用户的输入。我在控制台中输入的结果如下:
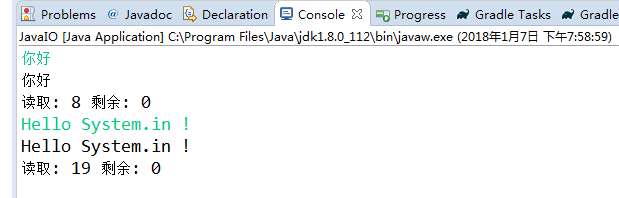
注意,System.in与文件输入不一样,它不存在“读取完毕”这回事。只要用户有输入,它就会拿到输入的数据;如果用户不输入,代码就会阻塞在 read() 方法处等待用户输出,因此这是一个死循环。
实际使用时,一般不会这样写在while循环内。想获得用户输入,可以使用一些工具类,例如 java.util.Scanner。
Scanner input = new Scanner(System.in);
// 读取并输出一行字符串
System.out.println(input.nextLine());
还有一点需要注意的是,不要把 System.in 当做普通的InputStream去调用 close() 方法。这样干的结果是当前程序再也无法通过它获得用户输入了。
读取网络数据
在示例代码中,我演示了如何从磁盘文件读取数据。事实上 http://www.jmecn.net 网站的首页和该文件的内容是一模一样的,可否直接读取网络数据呢?
可以,而且实现非常简单。只要修改“打开文件”,部分的代码。
原来的输入流是磁盘上的文件:
// 打开输入流
InputStream in = new FileInputStream("index.html");
现在改成网络连接:
URL url = new URL("http://www.jmecn.net/index.html");
HttpURLConnection conn = (HttpURLConnection)url.openConnection();
if (conn.getResponseCode() != HttpURLConnection.HTTP_OK) {
System.out.println("网络打开失败!");
return;
}
// 打开输入流
InputStream in = conn.getInputStream();
剩下的代码没有任何区别。
输出流
写文件
在上一节中,我把读取来的数据写到了一个 StringBuffer 中。如果文件超大的话,内存依然会爆炸。实际开发中,一般不会这么做。
正常的做法,要么是从源头限制文件的大小,不要读取超大文件;要么是根据需要来对数据进行实时处理,最常见的就是数据拷贝。
比如我可以把 index.html 的内容写到一个 index2.html 里,就相当于拷贝了一个文件。
对实例代码中的“读文件”部分做一点点改动,把 StringBuffer 换成文件输出流。
int len = in.available();
System.out.println("总字节数: " + len);
// 打开输出流
OutputStream out = new FileOutputStream("index2.html");
// 读取数据
len = 0;
byte[] data = new byte[1024];// 1KB
while( (len = in.read(data, 0, 1024)) != -1) {
// 写数据
out.write(data, 0, len);
System.out.printf("读取: %d 剩余: %d\n", len, in.available());
}
// 关闭输出流
out.close();
这段代码的作用就变成了复制文件,把 index.html 复制到 index2.html。
输出到控制台
事实上,我们常用的 System.out 本身也是一个输出流,只不过它是输出到控制台了。如果把 OutputStream 指向 System.out,结果就会在控制台中输出这个文件的内容。
int len = in.available();
System.out.println("总字节数: " + len);
// 打开输出流
OutputStream out = System.out;
// 读取数据
len = 0;
byte[] data = new byte[1024];// 1KB
while( (len = in.read(data, 0, 1024)) != -1) {
// 写数据
out.write(data, 0, len);
System.out.printf("读取: %d 剩余: %d\n", len, in.available());
}
// 关闭输出流
//out.close();
输出到网络
Java 的网络通信同样是基于I/O流的。对于网络服务器来说,通过InputStream可以获得用户的输入,通过OutputStream可以把数据发给客户端。
继续在示例代码的基础上加功能。创建一个ServerSocket来监听80端口(HTTP协议的默认端口),有任何客户端连接时,就把index.html的内容发送给它。
public static void main(String[] args) {
try {
// 启动Socket服务器,监听80端口。
ServerSocket server = new ServerSocket(80);
while(true) {
Socket client = server.accept();
// 打开输入流
InputStream in = new FileInputStream("index.html");
int len = in.available();
System.out.println("总字节数: " + len);
// 打开输出流
OutputStream out = client.getOutputStream();
// 读取数据
len = 0;
byte[] data = new byte[1024];// 1KB
while( (len = in.read(data, 0, 1024)) != -1) {
// 写数据
out.write(data, 0, len);
System.out.printf("读取: %d 剩余: %d\n", len, in.available());
}
client.close();// 断开客户链接
// 关闭输入流
in.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
这一段代码的改变主要是增加了一个死循环,因为服务器是持续运行的。当然正常情况下不会这样写死循环,一般都会有结束线程的方式,还会用连接池+线程池来处理并发访问。但我们这只是一个非常简单的例子,就不要纠结这种问题了。
在死循环中,通过 Socket client = server.accpet(); 来等待客户端访问。这个操作是阻塞的,如果没有客户访问,代码就会停在这里一直等待。当有客户链接时,就会读取 index.html 文件的内容,并通过 client.getOutputStream() 发送给客户。发送完毕之后立即执行 client.close() 方法断开链接,等待下一个客户链接。
// 打开输出流
OutputStream out = client.getOutputStream();
// 读取数据
len = 0;
byte[] data = new byte[1024];// 1KB
while( (len = in.read(data, 0, 1024)) != -1) {
// 写数据
out.write(data, 0, len);
System.out.printf("读取: %d 剩余: %d\n", len, in.available());
}
client.close();// 断开客户链接
运行程序,打开浏览器,输入 http://127.0.0.1/ 来访问本机服务器。不出意外你就会看到一个网页。
实际的HTTP服务器并不会这样简单得返回同一个页面,通常还会根据用户发送来的Http报文做一系列解析,然后调用服务端程序(Servlet/PHP等)来处理请求,但基本原理如此。
数据格式
前面的文章大致介绍了基于 InputStream 和 OutputStream 读写字节数据的方法。但实际应用中会遇到一些更细节的问题,例如:
- 我要读取3D模型文件,其中有浮点数、字符串、结构体等不同类型的二进制数据,应该如何用Java来解析?
- 我要读取CAD、点云(PT)等纯文本格式的数据,应该如何解析?
本节将介绍如何处理不同类型的数据格式。
字节序
在介绍具体数据类型的读取方法之前,请容我先介绍 字节序(Byte Order) 的概念。这并不是因为本人太啰嗦,而是因为字节顺序在读取数据时非常重要。
字节序的来历
谈到字节序的问题,必然牵涉到两大CPU派系。那就是PowerPC系列CPU和x86系列CPU。PowerPC系列采用big endian方式存储数据,而x86系列则采用little endian方式存储数据。那么究竟什么是big endian,什么又是little endian呢?
**端模式(Endian)**的这个词出自 Jonathan Swift 的小说《格列佛游记》。这本书根据将鸡蛋敲开的方法不同将所有的人分为两类:从圆头开始将鸡蛋敲开的人被归为Big-Endian,从尖头开始将鸡蛋敲开的人被归为Littile-Endian。小人国的内战就源于吃鸡蛋时是究竟从 大头(Big-Endian) 敲开还是从 小头(Little-Endian) 敲开,由此曾发生过六次叛乱,其中一个皇帝送了命,另一个丢了王位。
在计算机业Big-Endian和Little-Endian也几乎引起一场战争。在计算机业界,Endian表示数据在存储器中的存放顺序。采用 大端 方式进行数据存放 符合人类的正常思维 ,而采用 小端 方式进行数据存放 利于计算机处理。
大端的优势
什么叫做低序?什么叫高位?为什么说采用大端方式进行数据存放符合人类的正常思维?
例如:一个十进制的阿拉伯数字 1234 ,它表示一千二百三十四,书写顺序是 1、2、3、4。这就是大端(Big-Endian)字序。
- 数字
1是1234中的最高位(千),书写时排在第1(最低序); - 数字
4是1234中的最低位(个位),书写顺序排在第4(最高序)。
如果有人把“一千二百三十四”写成 4321,就叫小端(Little-Endian)。是不是感觉很反人类?
假设计算机中有一个无符号整数(4字节) 0x12345678,在内存中占4个字节。在大端、小端两种模式的计算机中,分别是这样存放的:
Big-endian:将高序字节存储在起始地址(高位编址)
低地址 高地址
---------------------------------------------------->
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| 12 | 34 | 56 | 78 |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
Little-endian:将低序字节存储在起始地址(低位编址)
低地址 高地址
---------------------------------------------------->
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| 78 | 56 | 34 | 12 |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
相比之下,按大端字节序存储的数据,是不是更符合人类的习惯?
小端的优势
Little-Endian的存在,主要是计算方便。
举一个例子,在计算表达式 14 * 37 时,要从个位开始,逐个计算到高位。
14 14 14
x 7 x 30 x 37
---- ---- ----
28 120 98
+ 7 +30 420
---- ---- ----
98 420 518
无论是乘法还是加法,计算时都是从低位开始的,并且逐渐累加进位。因此,把低位数存放在低序位置,优先参与计算,是一个很自然的事情。
其次,按Little-Endian存储时,1位(byte)、2位(short)、4位(int)、8位(long)等不同长度的整数,计算顺序都是一样的。而且还非常便于类型转换,只需要从低位开始截取就行了。
学习I/O操作为什么要了解字节序?
不同的操作系统、不同的编程语言,产生的文件格式是不一样的。当我们写的程序要处理其他平台、其他语言产生的数据时,就需要注意字节序的转换。否则就可能会出现 1234 被当做 4321 来处理的情况。
所有网络协议都是采用Big-Endian的方式来传输数据的,所以有时也会把Big-Endian方式称之为网络字节序。当两台采用不同字节序的主机通信时,在发送数据之前都必须经过字节序的转换成为网络字节序后再进行传输。
Java程序默认是以 Big-Endian 字节序来存储和读取数据的,而C/C++程序存储的字节序则与编译平台的CPU有关。大部分在Windows平台(x86的CPU)开发的C/C++程序,产生的文件都是 Little-Endian 字节序的。具体来说,如果你打算用Java程序来解析3ds格式的模型文件,如果忽略了字节序,恐怕得到的所有数据都是错误的。
整数
byte
读取byte类型的数据最简单,直接调用 InputStream 的 read() 方法即可。
public byte readByte(InputStream in) throws IOException {
byte b = in.read();
return b;
}
需要注意的是, Java中的byte、short、int、long都是有符号数,不支持unsigned类型 。为了保证读取字节时符号正确, in.read() 实际上返回的是一个 int 类型的数值。上面的代码等价于:
public byte readByte(InputStream in) throws IOException {
int n = in.read();
return (byte)n;
}
通常情况下,整数 n 的取值为 0~255。如果输入流中已经没有可读取的字符, read() 方法将返回 -1。为了防止输入流已经结束,应该在代码中加入 (n < 0) 的判断。若输入流已经结束,则抛出文件结束异常(End of File Exception)。
public byte readByte(InputStream in) throws IOException {
int n = in.read();
if (n < 0)
throws new EOFException();
return (byte)n;
}
unsigned byte
再说一遍,Java不支持无符号(unsigned)类型。 Java使用补码来表示带符号的数值。如果你把这个方法返回的byte类型当做数值来处理,它的取值范围将是 -128~127。
public static void main(String[] args) {
byte a = (byte)0x80;
System.out.println(a);
}
输出为: -128。
public static void main(String[] args) {
byte a = (byte)0xFF;
System.out.println(a);
}
输出为: -1
如果你读取字节数据只是用于存储图片数据,或者用于转换成字符串,前面写的 readByte() 方法没有任何问题。但如果你把它的返回值当做 unsigned byte 来计算,可能就会出现错误。
对于带符号整数。Java的处理方式是使用额外的字节来存储。比如把byte读取为int,把int读取为long。虽然浪费内存,但也没有更好的处理办法了。
public int readUnsignedByte(InputStream in) throws IOException {
int n = in.read();
if (n < 0)
throw new EOFException();
return n;
}
short
Java中的short由2个字节组成,可以连续调用2次 in.read() 方法,然后把结果转成一个 short 类型。转换时,需要注意字节序。
对于Little-Endian来说,应该这样处理:
int a = in.read();
int b = in.read();
short s = (short)((a<<0) + (b<<8));
对于Big-Endian来说,应该这样处理:
int a = in.read();
int b = in.read();
short s = (short)((a<<8) + (b<<0));
Java默认是按Big-Endian方式来读取数据的,方法如下:
public short readShort(InputStream in) throws IOException {
int a = in.read();
int b = in.read();
if ((a | b) < 0)
throw new EOFException();
return (short)((a << 8) + (b << 0));
}
Java中short类型的取值范围是 -32768 ~ 32767。
unsigned short
说第三遍,Java不支持无符号(unsigned)类型。 如果想要读取 unsigned short 类型,通常的做法是把它升格为 int 类型。
public int readUnsignedShort(InputStream in) throws IOException {
int a = in.read();
int b = in.read();
if ((a | b) < 0)
throw new EOFException();
return (a << 8) + (b << 0);
}
这个方法的返回值,取值范围是 0 ~ 65535
int
int类型使用4个字节来表示。按 Big-Endian 字节序读取,是这样的:
public int readInt(InputStream in) throws IOException {
int ch1 = in.read();
int ch2 = in.read();
int ch3 = in.read();
int ch4 = in.read();
if ((ch1 | ch2 | ch3 | ch4) < 0)
throw new EOFException();
return ((ch1 << 24) + (ch2 << 16) + (ch3 << 8) + (ch4 << 0));
}
按 Little-Endian 字节序读取,是这样的:
public int readInt(InputStream in) throws IOException {
int ch1 = in.read();
int ch2 = in.read();
int ch3 = in.read();
int ch4 = in.read();
if ((ch1 | ch2 | ch3 | ch4) < 0)
throw new EOFException();
return ((ch1 << 0) + (ch2 << 8) + (ch3 << 16) + (ch4 << 24));
}
取值范围: -2147483648 ~ 2147483647。
unsigned int
与前面一样,对数据做升格处理。把 int 升格成 long 读取。
Big-Endian 版的代码:
public long readUnsignedInt(InputStream in) throws IOException {
int ch1 = in.read();
int ch2 = in.read();
int ch3 = in.read();
int ch4 = in.read();
if ((ch1 | ch2 | ch3 | ch4) < 0)
throw new EOFException();
return (long)(((long)(ch1 & 0xFF) << 24) + (ch2 << 16) + (ch3 << 8) + (ch4 << 0));
}
注意,由于只有最高位字节可能带符号,因此要将 ch1 先转成long型,然后再进行算数左移。
Little-Endian 版的代码我就不写了。做法是一样的,只是换了高位、低位的顺序。
long
我想你应该已经明白是怎么回事了。无非就是读取8个字节,然后依字节顺序进行算术左移。
private byte readBuffer[] = new byte[8];
public long readLong(InputStream in) throws IOException {
if (in.read(readBuffer, 0, 8) < 0)
throw new EOFException();
return (((long)readBuffer[0] << 56) +
((long)(readBuffer[1] & 0xFF) << 48) +
((long)(readBuffer[2] & 0xFF) << 40) +
((long)(readBuffer[3] & 0xFF) << 32) +
((long)(readBuffer[4] & 0xFF) << 24) +
((readBuffer[5] & 0xFF) << 16) +
((readBuffer[6] & 0xFF) << 8) +
((readBuffer[7] & 0xFF) << 0));
}
同样,应该根据字节序来写具体的实现。如果是Little-Endian,就得把顺序颠倒过来。
浮点数
浮点数有两种精度,分别是单精度(float)和双精度(double)。一般float类型采用4字节存储,double类型采用8字节存储。使用Java读取浮点数时,一般先把字节当做 int 和 long 型的整数读取,然后调用 Float 和 Double 类的静态方法,把对字节进行转换。
float
Java的Float类提供了静态方法 intBitsToFloat(int bits) 方法,可以把一个4字节的整数(int)转换为4字节的单精度浮点数(float)。
通过调用前面实现的 readInt() 方法,配合Float.intBitsToFloat() 方法,就可以从输入流中读取float。
public float readFloat(InputStream in) throws IOException {
return Float.intBitsToFloat(readInt(in));
}
double
Java的Double类同样提供了 longBitsToDouble 方法,可以把一个8字节的长整型(long)转成一个8字节的双精度浮点数(double)。
public double readDouble(InputStream in) throws IOException {
return Double.longBitsToDouble(readLong(in));
}
字符串
定长字符串
在某些3D格式的文件中,为了尽量对齐数据结构,软件会把字符串固定为16字节、32字节、64字节、128字节等长度。解析这种文件时,需要注意字符串的实际有效长度。
假设一个字符串 "Hello World!",实际长度是12字节,保存到固定16字节的内存中,多余的4字节通常会用 '\0' 来填充。
在从输入流中读取字符串时,我们并不知道实际长度到底是多少,因此通常会先把整个定长字符串读取到一个缓存中。读取之后,再从开头查找 '\0' 出现的位置,用来判断字符串的实际长度。最后把实际用到的字节数据传给String的构造方法,用来生成一个String对象。
public String getString(InputStream in, int len) throws IOException {
if (len <= 0)
return "";
byte[] buf = new byte[len];
in.read(buf, 0, len);
int i;
for (i = 0; i < len; i++) {
if (buf[i] == 0)
break;
}
if (i == 0)
return "";
if (i == len)
return new String(buf);
return new String(buf, 0, i);
}
变长字符串
变长字符串比定长字符串常见得多,一般有两种存储格式:
- 字符串内容+结束符 '\0' 。
- 字符串长度+字符串内容。
前一种格式,每个学过C语言的人都不会陌生。C语言中通常会用一个 char 数组来保存字符串,字符串结尾以 '\0' 标识。
char str[16] = {'H', 'e', 'l', 'l', 'o', ' ', 'w', 'o', 'r', 'l', 'd', '\0'};
这种数据结构解析起来并不难,只要逐字节读取,遇到 0x00 就结束即可。
public static String getString(InputStream in) throws IOException {
StringBuffer stringBuffer = new StringBuffer();
char charIn = (char) in.read();
while (charIn != 0x00) {
stringBuffer.append(charIn);
charIn = (char) in.read();
}
return stringBuffer.toString();
}
后一种格式,常见于各种语言中的字符串类(string)。通常会先用2个字节(或4个字节)的无符号整数来存储字符串的长度,后面再保存字符串的实际内容,不需要用 '\0' 来结尾。
对于这种数据结构来说,先要调用前面实现的 readUnsignedShort() 或 readInt() 方法来获得字符串的长度,再调用 getString(InputStream in, int len) 方法来读取定长字符串即可。
具体的代码就不写了。
乱码原因
现在我们使用的高级编程语言,最初都是美国人发明的,他们的母语是英语。英语是一种拼音语言,他们只需要存储小写字母(a~z)、大写字母(A~Z)、阿拉伯数字(0~9)以及各种运算符号就行了,合起来都不超过128个符号。就算给键盘上每个功能键都增加一个编码,还把扑克牌上的四种花色都算进去了,美国标准编码(ASCII)字符集也不超过256个符号,使用单字节就足以表达任意符号了。
当计算机走向世界之后,世界各国的人们都在尝试在计算机上显示自己国家的语言。由于汉语的文字数量远远超过ASCII编码的数量,单字节是无法满足我们的,至少也得用双字节表示。例如 GBK 编码中的 0xCCCC 就表示汉字“烫”。
但是字符编码这件事并没有一个统一的标准,比如中国就有GBK、CP936、GB2312、BIG5等不同的编码。英语也仅仅属于拉丁语系中的一环,还有法语、俄语、德语、意大利语。各个国家都用自家的标准,结果互联网时代沟通非常不便。如果一个英国人的终端没有安装GBK编码,那么他访问中文网站看到的就是一堆乱码。
UTF-8/UTF-16/Unicode编码应运而生,势要统一地球上所有符号编码。这时候双字节不够用了,Unicode采用了多字节编码。但是,即使有标准,也未必会有人买账。比如中国软件已经使用了多年的GBK编码,为什么非要换成UTF-8编码?微软为了满足中国大陆市场的需要,Windows操作系统中的中文编码默认就是GBK。
在GBK编码环境下打开UTF-8编码的文件,或者反过来在Unicode环境下读取GBK编码的字符串,会怎么样?
还能怎么样,乱码了呗!
有诗为证:
手持两把锟斤拷,
口中疾呼烫烫烫。
脚踏千朵屯屯屯,
笑看万物锘锘锘。
棍斤拷
源于GBK字符集和Unicode字符集之间的转换问题。Unicode和老编码体系的转化过程中,肯定有一些字,用Unicode是没法表示的,Unicode官方用了一个占位符来表示这些文字,这就是:U+FFFD REPLACEMENT CHARACTER。那么U+FFFD的UTF-8编码出来,恰好是 '\xef\xbf\xbd'。如果这个'\xef\xbf\xbd',重复多次,例如 '\xef\xbf\xbd\xef\xbf\xbd',然后放到GBK/CP936/GB2312/GB18030的环境中显示的话,一个汉字2个字节,最终的结果就是:锟斤拷——锟(0xEFBF),斤(0xBDEF),拷(0xBFBD)。
烫烫烫屯屯屯
在Visual Studio中的Debug模式下,如果声明一个变量,但是没有初始化,微软会给未初始化的内存复制为0xCC。给为初始化的内存赋0xCC是有原因的,0xCC其实是INT3中断指令,所以如果在Debug模式下试图去执行这块未初始化的内存的话就会中断程序。
但VS中调试器默认的字符集是MBCS,而在MBCS中0xCCCC正好就是中文中的“烫”,所以显示出来就都是“烫烫烫..”。如果是用分配堆的内存,会初始化成0xCD,0xCDCD在MBCS字符集中就是“屯屯屯..”。
锘锘锘
BOM 是 Byte Order Mark 的缩写。是UTF编码方案里用于标识编码的标准标记,在UTF-16里本来是FF FE,变成UTF-8就成了EF BB BF。这个标记是可选的,因为UTF8字节没有顺序,所以它可以被用来检测一个字节流是否是UTF-8编码的。
- 锘
EFBB - 匡
BFEF - 豢
BBBF
出现这个问题肯定是你写网页的时候用了记事本 ,记事本在保存文件的时候把原本文件的编码改了记事本会默认保存为UTF-8的编码,而如果你原本网页是GBK编码的,就会出现乱码~BOM就是把一个Unicode保留字符U+FEFF,按照文件存储者的编码方式编码后,塞到文件内容的最前边。这样用不同的Unicode编码去解析文件头,就可以得知文件的编码方式和大小端顺序。结果就是文件头部多出来了两三个字节。
乱码处理
我曾经想制作一个工具,用来解决所有乱码问题。思路是根据数据的特征来统计字符串原本是用什么编码格式,然后按照对应的格式来解码。后来我只搞明白了一点,就是很难通过数据的内容来判断字符到底是什么编码。
例如一串数据是这样的: 0xCC 0xCE 0x1F 0xBF 0x3C 0xBA。它既可能是GBK编码,也可能是UTF-8编码,还有可能都不是。
因此所谓的乱码处理,其实是有前提条件的,就是已知数据的编码。如果不知道,那么就只能猜。在已知编码格式的前提下,Java 的 String 类为我们提供了根据字符编码来解析字符串的构造方法。
假设从输入流中读取了数据 byte[] data,用它来创建一个字符串,代码如下:
String str = new String(data);
若确定其编码格式为 GBK ,代码如下:
String str = new String(data, "GBK");
若想同时指定data中的有效数据和字符编码,代码如下:
String str = new String(data, offset, len, "GBK");
如果你发现字符串是乱码,想要尝试进行转码处理。可以使用 getBytes() 方法拿到 String 中的原始字节数据,再试着重新构建字符串。比如把按 "GBK" 编码的字符串重新按 "UTF-8" 编码生成字符串。
byte[] b = str.getBytes("GBK");
String str2 = new String(b, "UTF-8");
在处理网络传输的字符串时,通常会使用这样一个代码:
String str2 = new String(str.getBytes("ISO-8859-1"), "UTF-8");
它实际上是把数据按单字节编码取出,然后尝试转换成 UTF-8 编码。
C语言结构体
假设在C语言中定义结构体如下:
typedef struct Vert {
float x, y, z;
float nx, ny, nz;
float r, g, b, a;
float u, v;
struct Vert * next;
} Vertex, *LinkedVertex;
按上述方式定义顶点结构体,在C语言中只需要一行 fwrite 代码就可以保存到文件中。
Vertex vert = {
0.0, 0.0, 0.0,
1.0, 0.0, 0.0,
1.0, 1.0, 1.0, 1.0,
0.0, 0.0,
NULL
};
fwrite(&vert, sizeof(Vertex), 1, fp);
对于Java来说,读取文件中存储的结构体要复杂很多,基本上只能按照结构体存储的顺序逐一读取成员。而且还要注意是Little-Endian还是Big-Endian。
对于这样的纯数据结构体,通常会定义一个与结构体相似的Java类。
public class Vertex {
public float x, y, z;
public float nx, ny, nz;
public float r, g, b, a;
public float u, v;
public Vertex next;
}
然后利用前面写过 readFloat() 等方法来读取数据。
public Vertex readData(InputStream in) throws IOException {
Vertex v = new Vertex();
v.x = readFloat(in);
v.y = readFloat(in);
v.z = readFloat(in);
v.nx = readFloat(in);
v.ny = readFloat(in);
v.nz = readFloat(in);
v.r = readFloat(in);
v.g = readFloat(in);
v.b = readFloat(in);
v.a = readFloat(in);
v.u = readFloat(in);
v.v = readFloat(in);
readInt();// 读取指针
v.next = null;
return v;
}
注意,C/C++中的指针类型,通常会存储一个4字节的地址,因此可以用 readInt() 方法来拿到它的值。
由于指针存储的是C/C++程序运行时的内存地址,在Java程序中几乎没有什么用,所以通常不需要保存这个值。但在读取二进制数据时,也不能因为这个值无用而忽略它,所以单独调用了一次 readInt() 方法。
常用工具类
前文介绍了使用 Java I/O 来解析二进制数据时一些常见的问题和方法,但事实上大部分开发者并不会使用这么“原始”的方法来写代码。Java 中有一些工具类能够帮我们处理这些问题,只有在工具类无法满足需求时,程序员才需要自己写这种代码。
DataInputStream
java.io.DataInputStream 是一个专门用来读取二进制数据的类,它在InputStream上进行了一层包装,实现了 readByte()、readShort()、readFloat() 等方法。
使用时很简单,把一个 InputStream 传给 DataInputStream 的构造方法即可。
InputStream in = new FileInputStream("example.dat");
DataInputStream dis = new DataInputStream(in);
byte b = dis.readByte();
float f = dis.readFloat();
dis.close();
它的主要问题是默认使用 Big-Endian 方式读取数据,对于Little-Endian字节序的数据来说是灾难性的。要知道,大部分3D建模工具都是使用C/C++开发的,而且经常工作在Windows系统上,导致其文件存储的字节序都是Little-Endian。
解决办法很笨也很简单,前文我们已经了解了Little-Endian字节序的数据应该如何读取,自己实现一个Little-Endian 字节序的工具类就好了。
LittleEndian
jme3-core.jar 模块中已经实现了一个类似于 DataInputStream 的工具类,名为 com.jme3.util.LittleEndian。它的用法与 DataInputStream 一模一样,只是把字节序改成了 Little-Endian,免除了你自己写代码的工作量。
InputStream in = new FileInputStream("example.dat");
LittleEndian le = new LittleEndian(in);
byte b = le.readByte();
float f = le.readFloat();
le.close();
LittleEndian 类的源码如下: